사실상 Container의 생태계는 OCI라는 표준 규약을 따르기 때문에 어떤 컨테이너를 플랫폼을 사용하여도
유사한 방법으로 동작한다고 하였습니다.
쿠버네티스를 학습하기 전 컨테이너는 매우 매우 중요한 개념입니다. 해당 토픽에서는 Docker 플랫폼을 기반으로
컨테이너를 자세하게 다뤄보겠습니다.
Namespaces 격리
[실제 터미널] Nginx 컨테이너를 하나 띄웠습니다.
격리된 컨테이너 내부로 접속 (docker exec my-nginx /bin/bash로 접속 후 ps -ef)
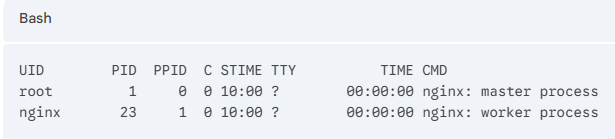
해당 터미널 프로세스 정보를 보면 Nginx 마스터 프로세스는 1번으로 Running 되어 있는 점을 볼 수 있습니다.
[실제 터미널] 실제 격리된 컨테이너 밖 호스트 프로세스 정보
호스트 프로세스에서 프로세스 확인 (ps -ef | grep nginx)

해당 터미널 프로세스 정보를 보면 Nginx 마스터 프로세스는 13452번으로 Running 되어 있는 점을 볼 수 있습니다.
위처럼 컨테이너 내부에서는 애플리케이션의 독립성을 보장하되, 외부(호스트)에서는 언제든 관찰하고 제어할 수 있는 일반 프로세스로 남겨두어 관리 효율성을 남기도록 제공 합니다.
Control Groups 자원의 격리
네임스페이스가 볼 수 있는 것을 제한한다면, cgroups는 리소스의 사용량을 제한합니다. 이러한 메커니즘이 없다면 컨테이너 하나가 CPU 100%를 써서 호스트 전체를 멈추는 일이 발생할 수 도 있습니다.
리눅스 커널에서 cgroup은 VFS(가상 파일 시스템) 형태로 구현되어 있습니다. 즉, 도커가 리소스를 제한한다는 행위의 기술적 실체는 커널이 노출한 특정 파일(/sys/fs/cgroup/...)에 숫자를 쓰는(Write) 시스템 콜입니다. 커널은 이 파일의 값을 읽어서 프로세스 스케줄링 알고리즘에 반영합니다.
실제 docker run을 실행했을 때, 기술적으로 어떤 순서로 cgroup이 적용되는지 로우 레벨 흐름입니다.
ㅁ Cgroup 디렉토리 생성
Docker Daemon(또는 containerd)이 libcontainer를 통해 /sys/fs/cgroup/cpu/docker/<Container-ID>/ 등의 디렉토리를 mkdir 합니다.
ㅁ 파라미터 주입
사용자가 입력한 --cpus=0.5 값을 계산하여, 위 디렉토리 내의 cpu.cfs_quota_us 파일에 50000이라는 바이트 스트림을 씁니다.
ㅁ 프로세스 격리
컨테이너의 메인 프로세스(PID)를 생성(fork/exec)한 직후, 해당 PID를 /sys/fs/cgroup/cpu/docker/<Container-ID>/cgroup.procs 파일에 씁니다. 이 순간부터 커널 스케줄러는 해당 PID를 스케줄링할 때, 연결된 cgroup 디렉토리의 설정값(Quota)을 참조하게 됩니다.
실제 제한은 리눅스 커널이 프로세스를 스케줄링하거나(CPU), 페이지를 할당할 때(Memory), 매 페이지 폴트(Page Fault)마다 cgroup의 메타데이터를 참조하여 물리적으로 차단하는 방식으로 동작합니다.
여기서 리소스를 다룸에 있어 매우매우 중요한 개념이 나옵니다.
Quota
정해진 시간 동안 쓸 수 있는 상하선이라는 개념입니다.
커널은 시간을 통째로 주는 게 아니라, 일정 주기(Period, 기본 100ms) 단위로 잘라서 관리합니다.
Quota는 이 100ms라는 주기 안에서 네가 CPU를 점유할 수 있는 시간은 딱 20ms야라고 상한선을 정해주는 것입니다.
Throttling
쓰로틀링은 자칫 잘못하면 매우 이해하기 어려운 개념이기 때문에
쉽게 설명자면, 정해진 컵 용량에 물을 가득 차면 어떻게 될까요?
물이 넘치게 됩니다. 컨테이너는 리소스에 물이 넘치게 되면 어? 저 컨테이너 물 넘치는데? 하고 수도 꼭지를 잠궈버립니다.
더 이상 물을 받을 수 없게 되어 컵(컨테이너)은 다음 급수 시간이 올 때까지 하염없이 기다리게 됩니다.
NET 네임스페이스 (네트워크 격리)
[실제 터미널] 컨테이너 내부 (ip addr)

컨테이너 내부에 NIC를 보면 eth0으로 일반적인 호스트에서 할당되듯 IP대역대를 사용하는 것을 볼 수 있습니다.
실제 호스트에서는 Docker0라는 인터페이스를 만들고 생성된 NAT네트워크에 컨테이너를 배포하게 됩니다.
CNI는 별도의 주제로 생성 하도록 하겠습니다.
MNT 네임스페이스 (파일 시스템 격리)
MNT 네임스페이스와 파일 시스템 격리는 리눅스 커널이 프로세스에게 착각(trick)을 주는 기술에 가깝습니다.
컨테이너 내부는 Ubuntu처럼 보이고, 호스트는 CentOS인 상황이 가능한 이유는 단순히 폴더를 분리했기 때문이 아니라, MNT Namespace(마운트 격리)와 OverlayFS(계층형 파일 시스템)라는 두 기술이 정교하게 결합되어 동작하기 때문입니다.
파일 시스템 격리는 2가지 단계를 거치게 됩니다. (준비 - 적용)
OverlayFS (준비)
호스트의 /var/lib/docker/... 경로에 우분투 이미지(읽기 전용)와 컨테이너 전용 쓰기 공간을 합쳐서 가짜 루트를 만듭니다.
MNT Namespace (적용)
컨테이너 프로세스가 생성될 때, pivot_root라는 시스템 콜을 사용해 방금 만든 가짜 루트를 프로세스의 / (루트)로 교체합니다.
[실제 터미널] 컨테이너 내부 (ls -F)

컨테이너 내부가 생각하기를 "나는 그냥 정석적으로 배포된 Ubuntu야" 라고 생각합니다.
[실제 터미널] 컨테이너 밖 호스트 (ls /var/lib/docker/overlay2/abcd1234.../diff/)
호스트는 CentOS 7로, 호스트 입장에서는 그저 수많은 오버레이 하나중 하나로 식별합니다.
IPC 네임스페이스 (프로세스 간 통신 격리)
Shared Memory 격리하여 다른 컨테이너가 다른 컨테이너로 메모리에 접근하지 못하게 제한합니다.
[실제 터미널] 컨테이너 밖 (ipcs -m)

[실제 터미널] 컨테이너 내부 (ipcs -m)

호스트가 메모리에 중요한 데이터를 올려놔도, 컨테이너는 그 메모리 주소 자체가 없기 때문에 공유될 수 없습니다.
USER 네임스페이스 (사용자 ID 격리)
[실제 터미널] 컨테이너 내부 (id)
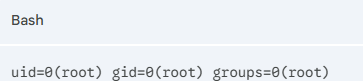
[실제 터미널] 컨테이너 밖 호스트

리눅스 커널은 프로세스를 실행할 때 /proc/<PID>/uid_map 경로에 ID를 어떻게 매핑할지 기록되어 있는 Mapping Table를 확인합니다. 결국 컨테이너는 root id라고 생각하지만, 실제 호스트밖에서는 uid_map 매핑되어있는 Ubuntu라는 사실인거죠
실제 쿠버네티스 파트로 넘어가게 되면 컨테이너의 내용은 매우 중요하지만 스킵된 상태에서 교육하는 경우가 많이 존재하기 때문에 유의 깊게 살펴보시면 좋을 것 같습니다.
'쿠버네티스' 카테고리의 다른 글
| [쿠버네티스] 자원에도 울타리가 필요하다: Cgroups와 OOM Killer (0) | 2026.03.11 |
|---|---|
| [쿠버네티스] "도커 네트워크가 어렵나요?" Docker0와 CNI로 풀어보는 컨테이너 통신 원리 (0) | 2025.11.24 |
| [쿠버네티스] "어디서든 돌아가는 컨테이너의 비밀" 표준 규격 OCI가 중요한 이유 (0) | 2025.10.26 |
| [쿠버네티스] 컨테이너의 대명사 '도커', 아키텍처로 이해하는 빌드와 배포의 메커니즘 (1) | 2025.07.28 |
| [쿠버네티스] 물리 서버에서 클라우드 네이티브까지: 서버 인프라 격변의 중심 '컨테이너' (1) | 2025.07.28 |


